Diccionario libre en español - Free Spanish dictionary
(Even though I write my blog in English, this post is in Spanish for obvious reasons. Click here to translate it with Google)
Este diccionario no es una "app" para usuarios. No lo puedes "instalar" en el móvil o el PC. Es una herramienta para investigadores e informáticos.
Descargar el diccionario (10MB .csv.gz; 140MB descomprimido)
Licencia: GNU FDL. Creo que es compatible con todas las licencias de los datos y programas usados para generarlo. Si no fuera así, mándame un correo por favor.
O bien, sigue leyendo el artículo para tener un poco de contexto y entender el fichero.
¿El primer chatbot en español?
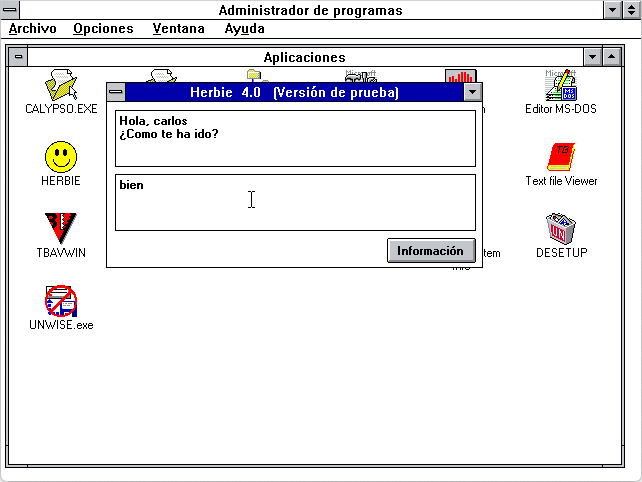
Uno de los programas más me fascinaba de niño fue "Herbie", un chatbot para MS-DOS y Windows 3.1, con el que pasé muchas horas muertas en aquella época pre-internet. No exagero cuando digo que ese software fue uno de los motivos que me impulsó a estudiar Inteligencia Artificial en la Universidad.
Casi no hay información de Herbie por la red, pero en su LEEME.TXT indica que el autor es un tal Rafael García de Avilés, e incluye su teléfono, al cual más de una vez he estado tentado de llamar.
Roberto Bonio
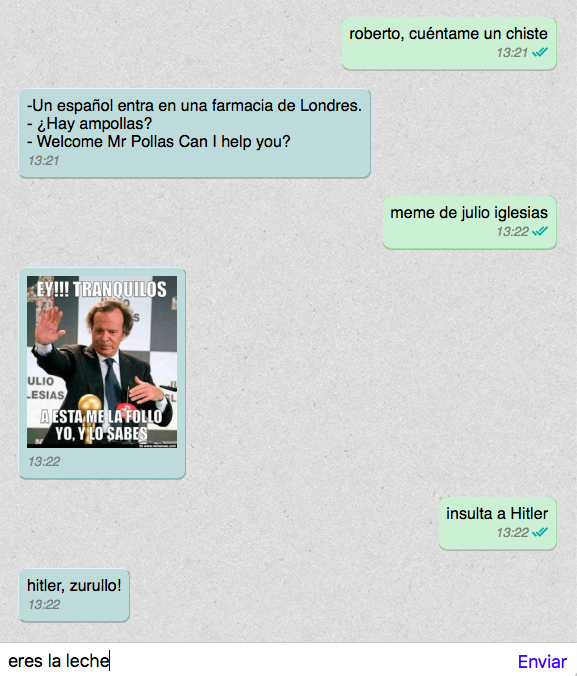
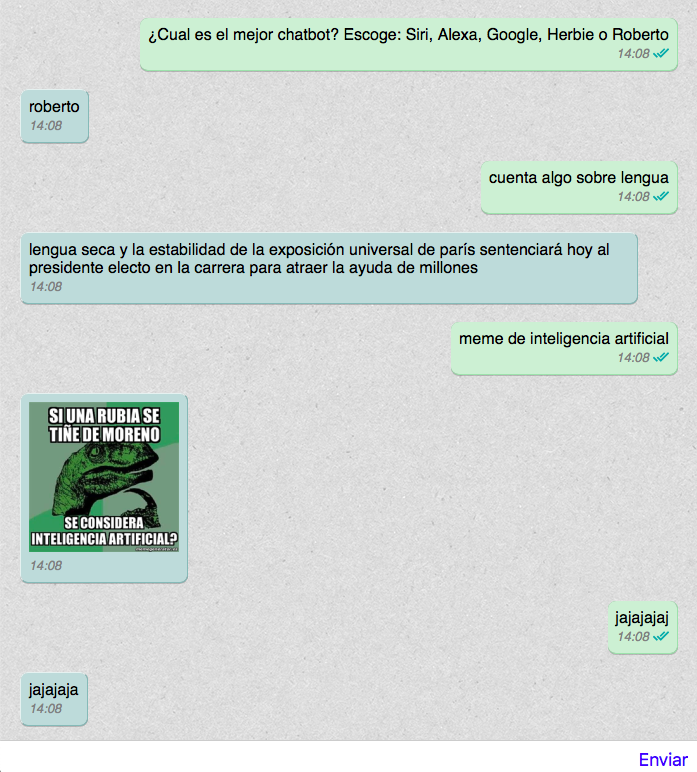
Allá por 2014 empecé a programar un chatbot propio, llamado "Roberto Bonio", que incluí en el grupo de Whatsapp con los amigos. Fue un verdadero hit; Roberto nos enviaba memes, te decía qué pizza escoger del menú, nos organizaba las cenas, y se reía de ti cuando decías tonterías.
Por desgracia, Whatsapp es muy agresivo baneando bots, y al no poder encontrar una manera estable de mantener el bot, lo acabé abandonando. Su última proeza fue hacer de DJ en mi boda, sí, como lo lees. Los invitados podían acceder a una página desde su móvil para pedir canciones, y Roberto las pinchaba en el Spotify conectado a un altavoz.
Bueno, ¿y a qué viene todo esto?
Actualmente estoy desarrollando una versión pública y mejorada de Bonio. Sólo servirá para echar unas risas, una especie de Herbie moderno con capacidades avanzadas de procesamiento del lenguaje.
Al intentar dotarlo de mejor inteligencia me he encontrado con que hay muy pocos recursos de NLP en español. En inglés hay una barbaridad, incluso APIs avanzadas (Microsoft, Google, IBM) de análisis morfosintáctico, análisis de sentimiento, etc, pero no en nuestro idioma.
Así que me puse manos a la obra, investigando y recopilando más de 500 MB de recursos lingüísticos en español.
Viendo el buen resultado, he decidido publicar el trabajo. Se trata de un diccionario libre en español, anotado, con un corpus extenso de palabras y variantes, aunque por desgracia sin definiciones.
El diccionario
Descargar el diccionario (10MB .csv.gz; 140MB descomprimido)
Licencia: GNU FDL. Creo que es compatible con todas las licencias de los datos y programas usados para generarlo. Si no fuera así, mándame un correo por favor.
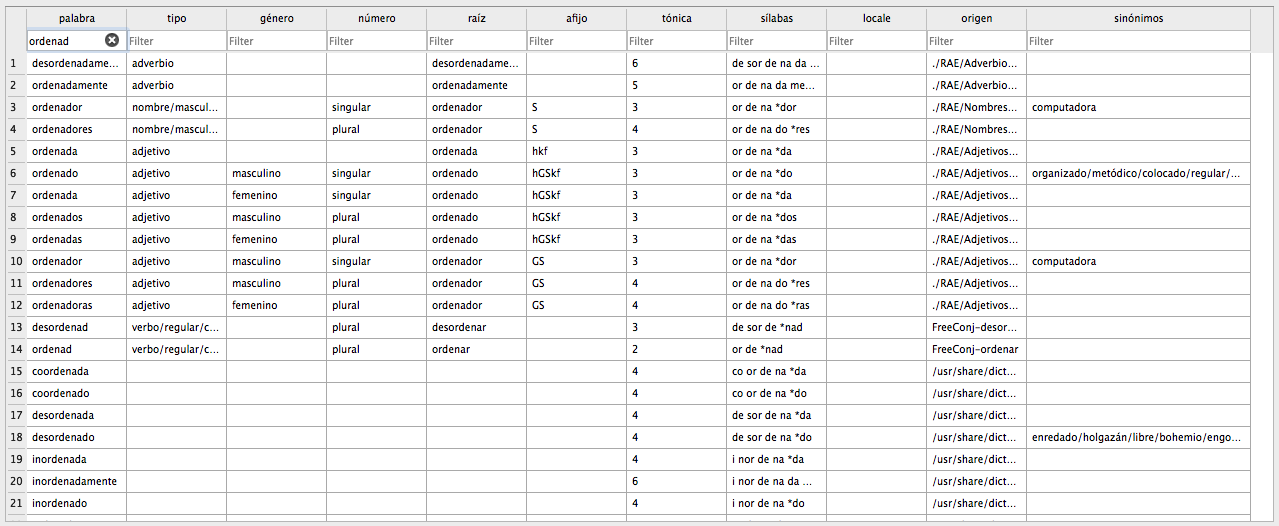
El diccionario es un fichero csv con las siguientes columnas:
palabra: la palabra en cuestióntipo: si es artículo, nombre, pronombre, adjetivo, etc.- Los nombres tienen categorización adicional:
nombre/<tipo nombre>: topónimo, nombre común, si es masculino, femenino...
- Los verbos tienen categorización adicional:
- si es un infinitivo:
verbo/<tipo>/infinitivo, donde<tipo>estransitivo,pronominal, etc. - si es una forma conjugada:
verbo/<tipo>/conjugado/<tiempo>/<persona>/<modelo de conjugación>
- si es un infinitivo:
- En general, tendrás que hacer un listado de este campo para ver todas las opciones. Es un poco un cajón de sastre.
- Los nombres tienen categorización adicional:
género: masculino, femenino, o neutronúmero: singular o pluralraíz: si es una palabra declinada (nombre, verbo, adjetivo...) este campo indica la palabra originalafijo: el afijo de RLAEtónica: la sílaba tónicasílabas: separación en sílabas de la palabralocale: si esta palabra corresponde a una región específica del españolorigen: corpus o fichero de procedencia de la palabrasinónimos: sinónimos para dicha palabra, separados por barras. Sólo aparecen en palabras raíz.
Errores
El fichero ha pasado una inspección ocular, y además todas las líneas del CSV son válidas. Sin embargo, es posible que aparezcan errores puntuales.
Si detectas un error GRAVE DE FORMATO, que impide el procesamiento del fichero, envíame un correo y lo revisaré. No tengo capacidad para revisar los errores lingüísticos, de los que habrá muchos. Este es un corpus generado informáticamente.
Estos son los errores actuales detectados:
- Es muy habitual que falte información y/o haya campos vacíos
- Puede haber palabras mal acentuadas. He declinado el género/número de manera simple (-o, -a, -os, -as, etc.)
- Hay errores de categorización de palabras. Aparecen adverbios o adjetivos como nombres, y problemas similares
- Falta de consistencia al tipificar los nombres y verbos
- Las sílabas de palabras compuestas o frases pueden estar mal
Pese a todo, el diccionario es muy usable y de alta calidad, especialmente si tenemos en cuenta que las fuentes de datos provienen de voluntarios.
Conversión a SQL y rendimiento
Mi objetivo era generar un único mega-fichero de fácil distribución y que fuera parseable informáticamente. Como, además, tampoco soy lingüista, no he sido capaz de diseñar una estructura de datos mejor.
En cualquier caso, pienso que es suficiente, y que en el peor de los casos sólo habrá que hacer dos queries al fichero para acceder a toda la información relacionada.
Mi recomandación, al tratarse de un fichero muy grande, es pasarlo a una base de datos. Yo he hecho lo siguiente:
$ sqlite3 palabras.sqlite
sqlite> create table palabras
(
palabra text,
tipo text,
género text,
número text,
raíz text,
afijo text,
tónica integer,
sílabas text,
locale text,
origen text,
sinónimos text
);
sqlite> create index palabras_palabra_index on palabras (palabra);
sqlite> create index palabras_raíz_index on palabras (raíz);
sqlite> create index palabras_sinónimos_index on palabras (sinónimos);
sqlite> .mode csv
sqlite> .import palabras.csv palabras
sqlite> .quit
De esta manera es mucho más rápido consultar el diccionario, y se pueden hacer queries complejos,
del tipo SELECT palabra FROM palabras WHERE sinónimos LIKE '%/excelente/%' AND tipo LIKE 'nombre%'
en milésimas de segundo.
Licencia, origen de datos y referencias
Ha sido realmente difícil encontrar buenas fuentes de palabras, por lo que hay que agradecer la tarea titánica a las personas que han generado estos corpus libres.
Es importante mencionar la falta de datasets de recursos públicos: Universidades y RAE proveen de "buscadores" y "herramientas" online, pero no publican las fuentes de datos para poder trabajar con ellas. ¡¡Muy mal!!
El español en la red es un lenguaje que está a años luz del inglés. Nos faltan herramientas y corpus libres para poder avanzar en IA y procesamiento de lenguaje natural en nuestro idioma. Hasta que no haya recursos disponibles, los investigadores y científicos seguiremos prefiriendo el inglés.
Recursos usados para la generación de palabras.csv:
- El mejor diccionario tanto en cantidad de palabras como en calidad de las anotaciones es el del Recursos Lingüísticos Abiertos del Español, usado en herramientas libres como LibreOffice.
- Los verbos los he conjugado con el FreeConj-TIP, de Carreras-Riudavets et al.
- El silabeador también es del mismo grupo, Silabeador TIP, en este caso de Hernández-Figueroa et al.
- Diccionario wspanish del GNU Ispell
- Sinónimos del RLAes
- Algunas correcciones manuales por mi parte, dentro de mis limitaciones
En resumen, gracias a las comunidades de software libre y a un grupo de investigación que publica sus datasets me ha sido posible generar este recurso.
Trabajo futuro
Por orden de importancia, los siguientes pasos serían:
- Asegurarse de usar las formas declinadas correctas (femeninos/plurales) que se han generado con un algoritmo simple, y revisar en general la ortografía del diccionario
- Revisar la calidad morfológica. Como apunto más arriba, hay bastantes errores de bulto en la clasificación de las palabras que dificultarán el análisis morfosintáctico de las frases usando este diccionario
- Inclusión de definiciones. Lo más sencillo sería parsear el Wikcionario, pero es una herramienta pensada para texto, no APIs, y la información no está estructurada.
- Análisis de sentimiento de las palabras. Algo tan básico como añadir una columna
sentimientoa cada palabra, con los valorespositivoonegativosería de increíble utilidad para el procesamiento de textos, por ejemplo, en redes sociales
Conclusión
Mi esfuerzo se ha centrado en unificar y centralizar datos ya existentes, así como el uso de herramientas para generar datos derivados. Gracias a unas cuantas horas scripteando ficheros txt y csv he podido generar con poco esfuerzo un corpus bastante completo.
Espero haber generado un recurso útil tanto para aficionados al NLP como para investigadores que necesiten acceso a un diccionario de calidad razonable.
Acabo con un mensaje para las instituciones: ¡Publicad siempre vuestros datasets! Las aplicaciones web de consulta no sirven de nada si no tienen una API potente y permiten volcar los datos.
Por mi parte, he cumplido el objetivo que me propuse: tener un buen diccionaro para mejorar el generador de Markov y que Roberto diga chorradas con más gracia.
Descargar el diccionario (10MB .csv.gz; 140MB descomprimido)
Licencia: GNU FDL. Creo que es compatible con todas las licencias de los datos y programas usados para generarlo. Si no fuera así, mándame un correo por favor.